TensorFlow学习笔记(三)
激活函数
在存在的数据集中有些数据可以简单的用一条直线或者一个平面来划分数据,则称这些为线性可分。但是有些数据是不可以分的,这样就没有办法用一条直线或者平面来区分数据。
这时候可以通过激活函数(Activation function)入一个非线性的激活函数增加模型的表达能力。
常见的激活函数有
- sigmoid
$$
sigmoid(x)=\frac{1}{1+e^{-x}}
$$

cs231n中提到这个一些缺点:
会产生梯度消失、不关于原点中心对称会导致$f(\sigma{w_ix_i+b})$中的梯度恒正或恒负收敛速度慢、计算耗时
- tanh
$$
tanh(x)=\frac{1-e^{-2x}}{1+e^{-2x}}
$$

这里只解决了sigmoid中的不对称的问题、通常情况下能用tanh就不采用sigmoid。
- ReLU
$$
ReLU(x)=\begin{cases}
0& \text{x ≥ 0}\
x& \text{x < 0}
\end{cases}
$$

这个是最常用的一个激活函数
优点: 收敛比较之前的激活函数会加速6倍左右、在正数范围内不会发生梯度消失、计算速度快
缺点: 不关于0中心对称、x<0时梯度消失、0点梯度未定义
初始化时,ReLU神经元将偏置值设为很小的正数(eg.0.0001)而不是0
下面这几个都是ReLU的变体
Leaky ReLU
$$
f(x)=max(0.01x,x)
$$
- PReLU
$$
f(x)=max(\alpha x,x)
$$
- ELU
$$
f(x)=\begin{cases}
x& \text{x>0}\
\alpha(e^{x}-1)& \text{x ≤ 0}
\end{cases}
$$
- Maxout
$$
f(x)=max(w^{T}{1}x+b_1,w^{T}{2}x+b_2)
$$
损失函数
cs231n Loss functions这里有损失函数的详细解释
之前介绍的只是对于二分类的网络处理。虽然可以设置多个阈值来实现多分类但是实际解决问题不会这么处理。这样就可以应用损失函数解决多分类问题。
假设神经网络以一个n维数组作为输出结果,假设以识别手写体的数字1为例,则输出结果越接近[0,1,0,0,0,0,0,0,0,0]越好,评估训练得到的向量与这个准确的实际的向量的方法最常采用交叉熵(cross entropy)的评估方法。
如果给出2个概率分布p,q 通过q来表示p的交叉熵为:
$$
H(p,q)=-\Sigma{p(x)\log{q(x)}}\
p:true lable\
q:prediction
$$
交叉熵刻画的是两个概率分布之间的距离,然而神经网络的输出不一定是一个概率分布,这时就需要某种方法将神经网络前向传播的结果变成概率分布。softmax回归(softmax regression)是最常用的方法。
假设神经网络的输出为$y_1,y_2 \cdots y_n$,那么经过softmax回归之后得到的输出为:
$$
softmax(y_i)=\frac{e^{y_i}}{\Sigma^n_{j=1}{e^{y_j}}}
$$
- 在TensorFlow中提供了交叉熵和softmax回归的函数
1 | # 一般都交叉熵会与softmax一起使用: |
- 如果解决的不是分类问题,而是预测房价什么的输出是一个实数,这时最常用的是均方误差(MSE,mean squared error)
$$
MSE(y,y’)=\frac{\Sigma^n_{i=1}{(y_i-y’_i)}^2}{n}\
y_i是第i个数据正确答案,y’_i是数据网络的预测值。
$$
1 | mse = tf.reduce_mean(tf.square(y_ - y)) |
神经网络优化算法
梯度下降算法Gradient Descent
- Gradient Descent (GD)
$$
\theta_i :=\theta_i-\alpha\frac{\partial}{\partial \theta_i}J(\theta)
$$
$$
\begin {aligned}
\frac{\partial}{\partial \theta_i}J(\theta) &= \frac{\partial}{\partial \theta_i}{\frac{1}{2}}{(h_\theta(x)-y)^2} \
&=(h_\theta(x)-y) \frac{\partial}{\partial \theta_i}(\theta_0x_0+\cdots+\theta_nx_n-y) \
&=(h_\theta(x)-y)x_i
\end {aligned} \
$$
所以$\theta_i:=\theta_i-\alpha(h_\theta(x)-y)x_i$,其中$\alpha$为学习速率
性质: 一定会结束,取决于初始值,局部最小值梯度为0. 来自Andrew Ng: Stanford Machine Learning
- Batch Gradient Descent
$$
\theta_i:=\theta_i-\alpha\sum_{j=1}^n (h_\theta(x^{(j)})-y^{(j)})x_i^{(j)}
$$
遍历所有数据,适用于较小数据
- Stochastic Gradient Descent (SGD)
执行此算法时,每次不一定按照局部最小值方向前行,最终在局部最小值附近。
- 还有一种利用矩阵运算的方法求得$J(\theta)$的最小值
$$
\theta = (x^Tx)^{-1}x^Ty
$$
直接给出结论,推导过程较长,这里不写了。。具体可以参考Ng的机器学习课程中有具体推导见 Andrew Ng: Stanford Machine Learning
更多的优化算法的具体情况可以看cs231n
cs231n有两张图提供了对比


在TensorFlow中的优化算法
在官方的API文档中有专门的一节给出优化算法的API: Gating Gradients
- 常用的有:
- tf.train.AdagradOptimizer
- tf.train.MomentumOptimizer
- tf.train.AdamOptimizer
学习率的设置
学习率决定了参数每次更新的幅度,如果幅度过大,那么可能导致参数在极优值的两侧来回移动。
学习率过大过小都可能导致不理想的优化效果,参数过大可能导致不在最小值收敛,参数过小虽然能保证收敛,但可能会大大降低优化速度。
TensorFlow提供了一个指数衰减的学习速率tf.train.exponential_decay,通过这个函数可以先使用较大的学习率来快速得到较优解,然后随着迭代的继续减小学习率,是的模型在训练后期更加稳定。
1 | decayed_learning_rate = learning_rate * decay_rate ^ (global_step /decay_steps) |
1 | # 实际的程序代码: |
过拟合问题
在真是的应用中,常常会遇到模型模拟了训练数据,而我们的目标确实让模型去对未知的数据做出判断。所谓过拟合是指当模型过于复杂之后,它会”记住”每个训练数据。如果模型的参数比训练的总数据还多,会导致损失函数最终为0。这种情况虽然对训练集的拟合较好,但是对于验证集则很差。
正则化
为了避免过拟合的问题,一个最常用的方法是正则化(regularization)。正则化是在损失函数中加入刻画模型复杂程度的指标。假设刻画模型在训练数据上的表现的损失函数为$J(\theta)$,那么优化时,不直接优化$J(\theta)$,而是优化$J(\theta)+\lambda R(w)$。其中$R(w)$刻画的是模型的复杂程度,而$\lambda$表示模型复杂损失在总损失中的比例。
这里$\theta$表示神经网络中所有的参数,包括边上的权重w和偏置b。一般来说模型复杂度只由权重w决定。常用的刻画模型复杂度的函数$R(w)$有两种。
cs231n里有正则化的详细介绍
- L1正则化(L1 Regularization)
$$\sum_k \sum_l (w_{k,l})$$
- L2正则化(L2 Regularization)也称Ridge(岭回归)
$$\sum_k \sum_l (w_{k,l})^2$$
L0正则化的值是模型参数中非零参数的个数。
L1正则化表示各个参数绝对值之和。
L2正则化标识各个参数的平方的和的开方值。
可能这些公式不同的地方公式会不同,我用的是cs231n课程中的写法,但都表示同一个意思。
还有一些可能会用到的
- Elastic Net 这是一种可以看出L1+L2的合成。
$$R(w)=\sum_k \sum_l \beta w_{k,l}^2+|w_{k,l}|$$
- Max norm constraints 类似于限制每个神经元w的最大值。论文
Max norm constraints. Another form of regularization is to enforce an absolute upper bound on the magnitude of the weight vector for every neuron and use projected gradient descent to enforce the constraint. In practice, this corresponds to performing the parameter update as normal, and then enforcing the constraint by clamping the weight vector $\vec{w}$ of every neuron to satisfy $\Vert \vec{w} \Vert_2 < c$are on orders of c 3 or 4. Some people report improvements when using this form of regularization. One of its appealing properties is that network cannot “explode” even when the learning rates are set too high because the updates are always bounded.
- Dropout 随机失活一部分神经元
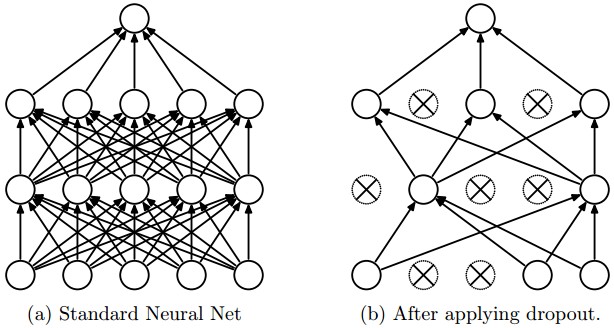
- 在TensorFlow中提供了带正则化的损失函数:
1 | # 这是正则化函数的定义 |
1 | # 这里是使用L1、L2正则化的实例 |
在简单的数据网络这样可以很好地计算带正则化的损失函数,但是参数增多时,这样的方式可能导致损失函数的loss的定义很长,可读性差且容易出错。但更主要的是,当网络结构复杂之后定义网络结构的部分和计算损失函数的部分可能不在一个函数中,这样通过变量这种方式计算损失函数就不方便了。为了解决这个问题,可以使用TensorFlow中提供的集合(collection)。它可以在一个计算图中(tf.Graph)中保存一组实体(比如张量)。
1 | import tensorflow as tf |

